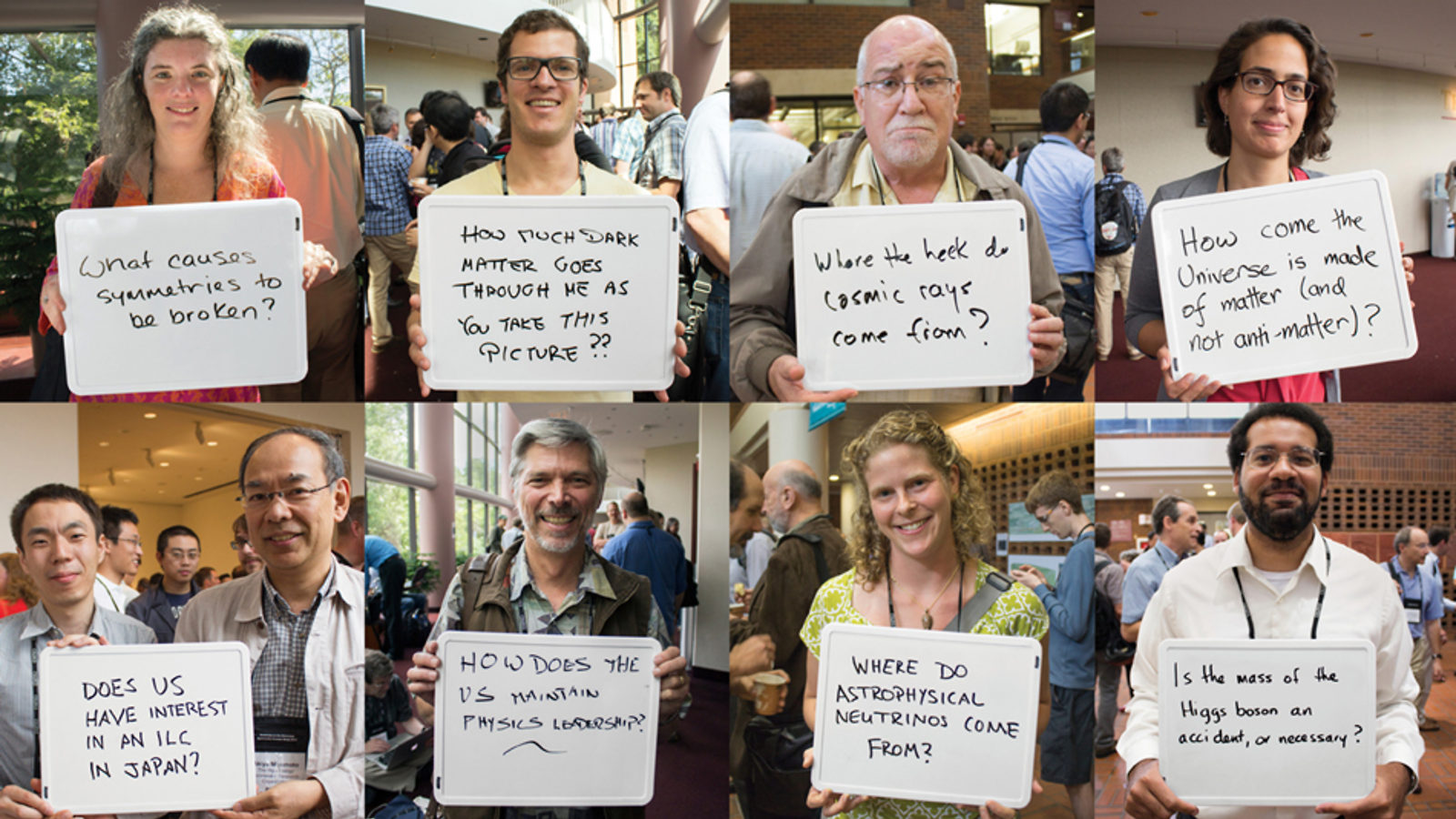
Bring hundreds of smart physicists together and what do you get? Lots of questions!
This summer, more than 700 particle physicists from nearly 100 universities and laboratories across the United States came together on the University of Minnesota’s Twin Cities campus for the Snowmass Community Summer Study meeting. There, they discussed the decades ahead in US particle physics, carefully considering the next steps in their studies of energy, matter, space and time.
During coffee breaks, symmetry asked attendees to share open questions in particle physics. Here’s a sample of what particle physicists think about and what they hope to discover in the coming decades. (A poster of these questions is also available here.)

Steve Wimpenny
University of California, Riverside

Stefan Funk
SLAC/Stanford University
Robin Erbacher
University of California, Davis
Kevin Lesko
Berkeley Lab

Erik Ramberg
Fermilab
Elizabeth Worcester
Brookhaven National Lab

Kanika Sachdev
University of Minnesota

James Matthews
Louisiana State University

Akiya Miyamoto
High Energy Accelerator Research Organization
Hiroaki Ono
Nippon Dental University
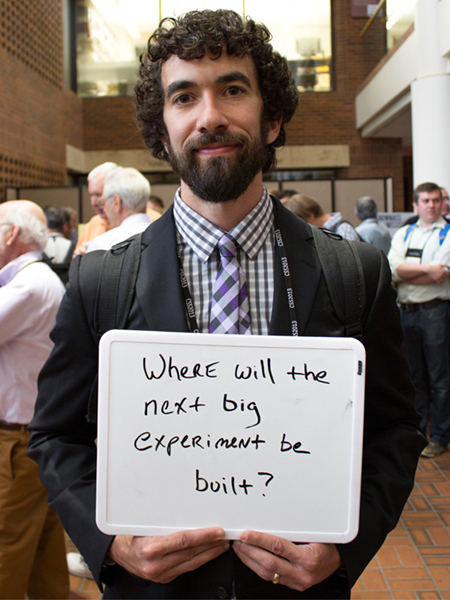
Jonathan Asaadi
Syracuse University
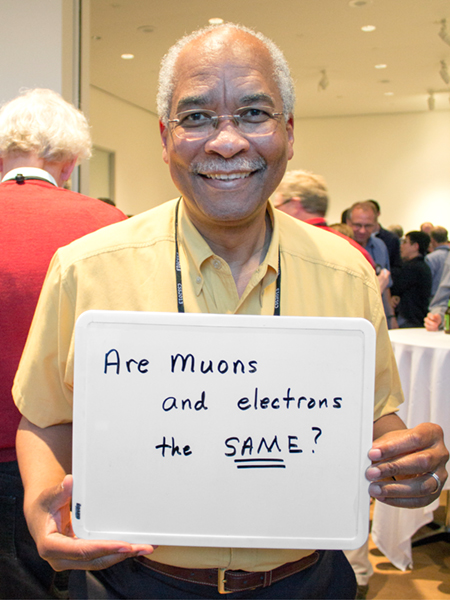
Herman White
Fermilab

Chien-Yi Chen
Brookhaven National Lab

Hao-Yi Wu
University of Michigan
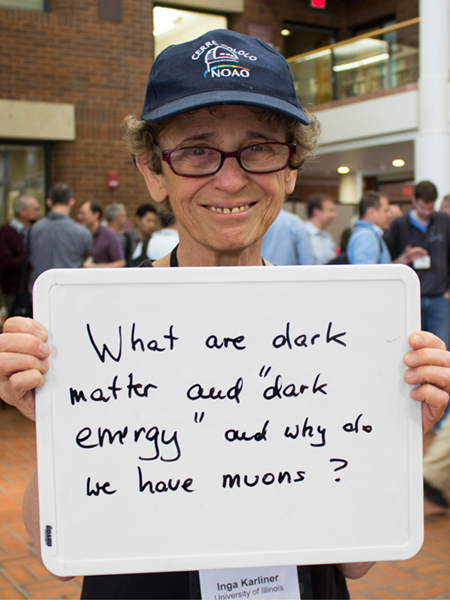
Inga Karliner
University of Illinois, Urbana-Champaign

Ian Shipsey
Purdue University

Richard Ruiz
University of Pittsburgh

Marcelle Soares-Santos
Fermilab
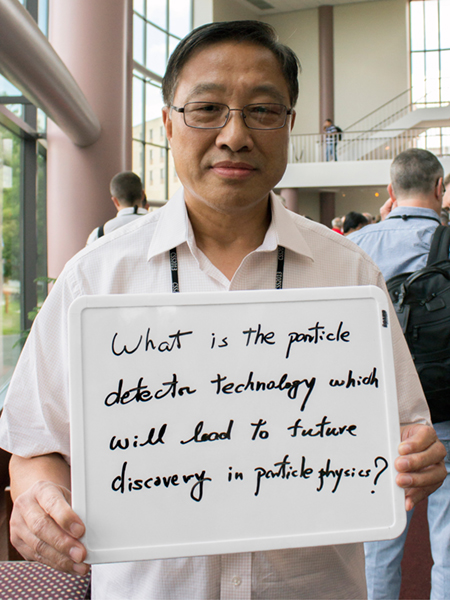
Ren-Yuan Zhu
Caltech

Wade Fisher
Michigan State University
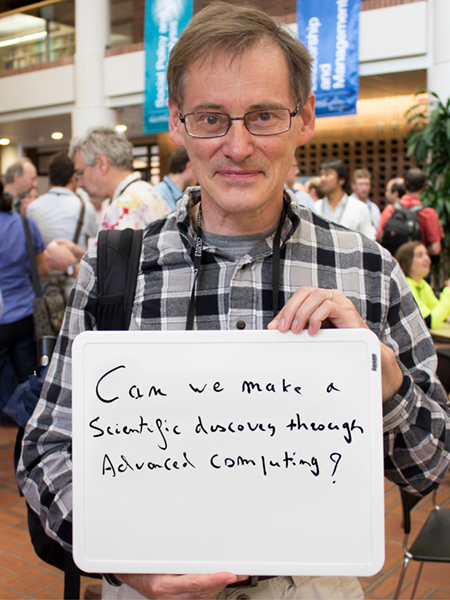
Paul Lebrun
Fermilab
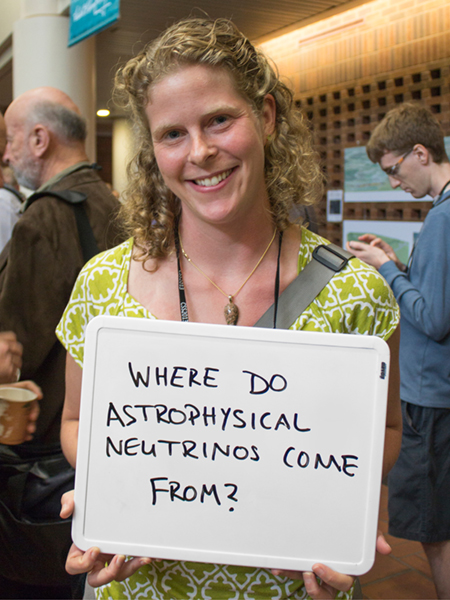
Abigail Vieregg
Harvard University
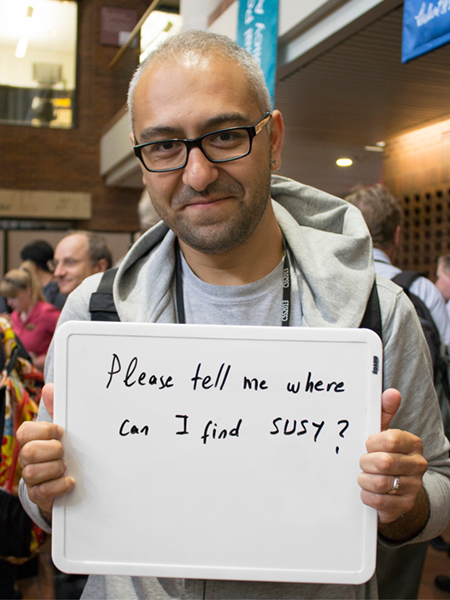
Altan Cakir
DESY

Peter Onyisi
University of Texas, Austin
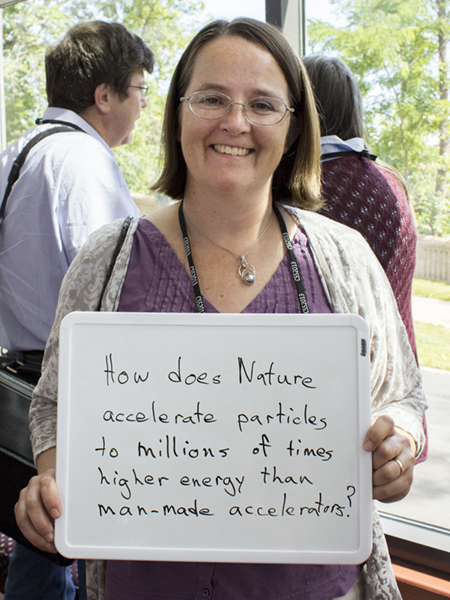
Brenda Dingus
Los Alamos National Lab
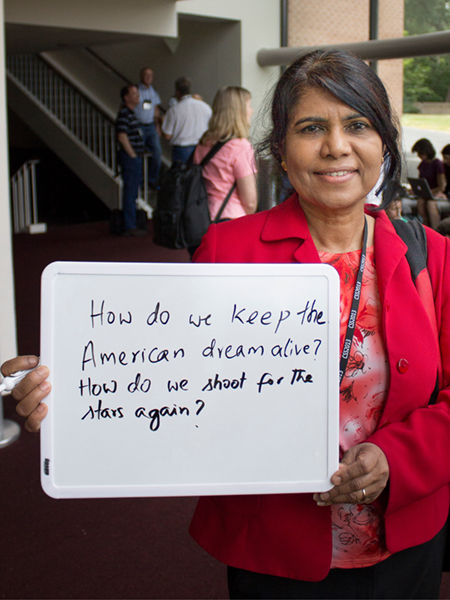
Pushpa Bhat
Fermilab

Gabe Shaughnessy
University of Wisconsin
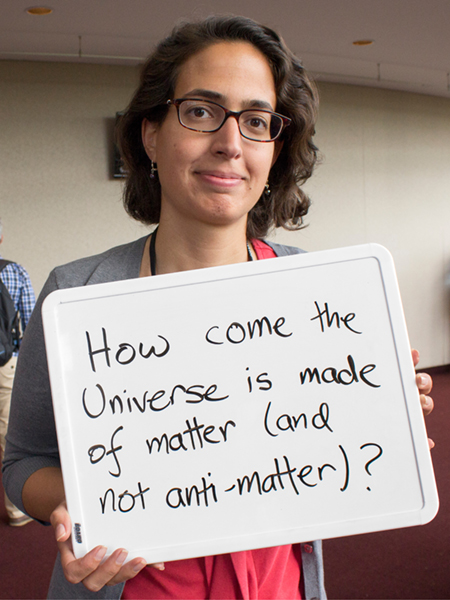
Alysia Marino
University of Colorado
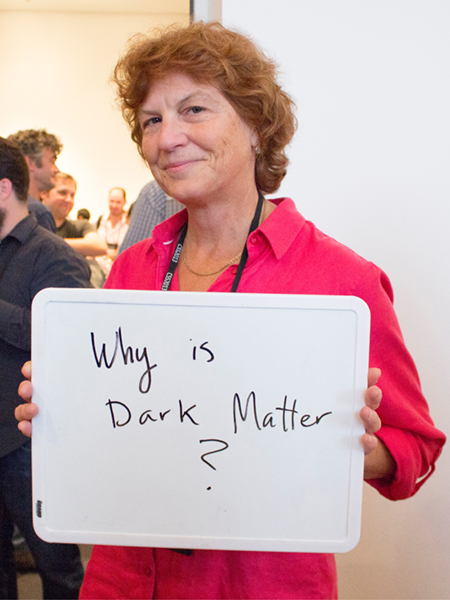
Prisca Cushman
University of Minnesota
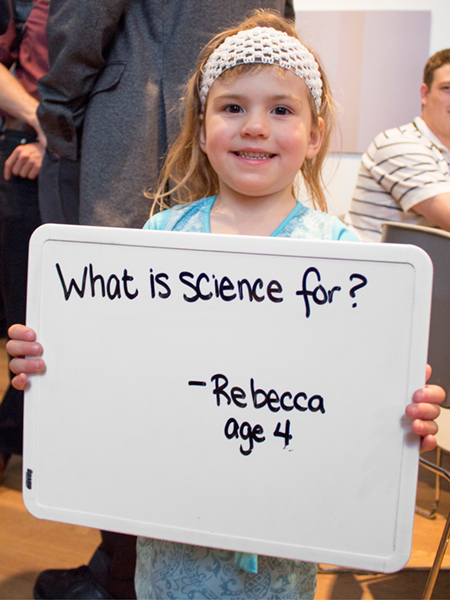
Rebecca (age 4)
Daughter of Matthew Strait, University of Chicago
Ian Shipsey
Purdue University
Like what you see? Sign up for a free subscription to symmetry!









