Nearly everything about high-energy physics research is big—the thousands of scientists on a single experiment, the miles-long accelerators, the stories-high detectors. Yet “big” doesn’t begin to describe the torrent of data that gushes out of high-energy physics experiments every day. Out of sheer necessity, particle physicists are virtuosos at plying vast troves of data into meaningful physics.
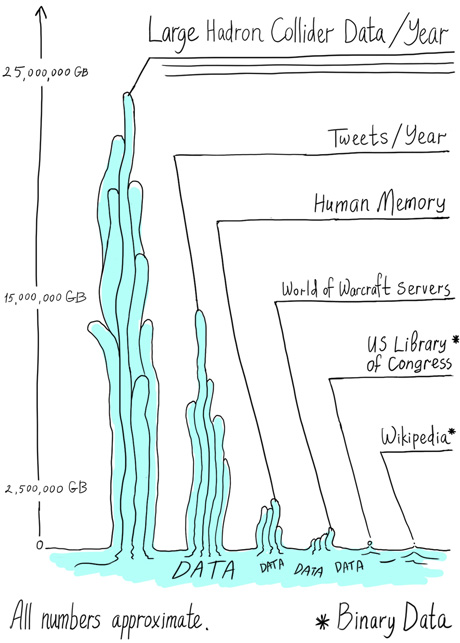
Consider CERN’s Large Hadron Collider. A year of collisions at a single LHC experiment generates close to 1 million petabytes of raw data. If they kept it all, scientists would be looking at enough data to fill roughly 1 billion good-sized hard drives from a computer retailer.
“You can think about walking into a Best Buy with a big checkbook and saying, 'Give me 10,000 disks,’” says Argonne National Laboratory scientist Tom LeCompte, a collaborator at CERN’s ATLAS experiment. “It’s expensive, but it’s not unimaginable.” But walking in and saying, “Give me a billion disks”? That, he says, would be inconceivable.
Filtering and managing large data sets is of course not exclusive to particle physics. Researchers in all fields of science, government and industry are mapping ever-increasing amounts of information in ever-greater detail. The trend is known as big data.
The work of the experimental science community is to bring those volumes of complex data within the scale of the imaginable.
It’s a goal particle physicists have been working on for decades.
In 1930, Ernest O. Lawrence, the father of particle accelerators, built the first hand-held cyclotron to accelerate protons. Each decade since has seen larger and more powerful accelerators that produced heavier and more exotic particles. By colliding speeding particles into stationary targets or into one another and then analyzing the complex byproducts, researchers learn about the structure of the universe and the forces that govern it. As the questions they addressed became more complex, experiments grew and so too did the data—and the behind-the-scenes work needed to make that data manageable.
“You do what you have to do in order to get the physics done,” says physicist Tom Nash, who created Fermilab’s Advanced Computing Program in 1981.
At first, that meant tweaking off-the-shelf technology, from the intelligent application of small microprocessors for routing information to the design and construction of computer farms that would accommodate the large data volumes.
By the 1990s, computers for Fermilab’s CDF experiment were processing hundreds of terabytes a year—enough to fill thousands of today’s highest-storage iPhones and a huge amount of data in the era before Google’s ascendancy.
As off-the-shelf technology was rarely up to the task of handling data from the experiments, high-energy physicists developed ways to make the data more manageable. They began recording only a small subset of the particle collisions. They started building their own storage solutions. They came up with new ways to transmit data around the globe. And they learned to share the load among many research institutions and groups.

One of the simplest ways to lessen the load of big data is to make it smaller.
Since the 1950s, high-energy physicists have had to contend with culling data immediately after each particle collision. By the 1970s they had come up with highly sophisticated and automated ways—called triggers—to separate interesting collisions from the more common ones.
For example, at the Large Hadron Collider, where proton bunches collide 20 million times in a single second, only a few out of every 1,000 collisions produce the sought-after physics. So researchers set up a trigger system that examines every particle collision to conclude, based on pre-determined criteria, whether the collision produced particles of interest. If so, the data from that collision continue on to be recorded. If not, they’re discarded.
Over the years, physicists have improved trigger systems to the point that they can evaluate all the data from a collision and discard the information they don’t need in millionths of a second. At that rapid pace, no unwanted data ever clogs the pipes.
At the LHC—and all modern high-energy physics experiments—three levels of trigger discard, on average, all but 1 in every 100,000 particle interactions in the detector.
“You can’t afford to keep it all,” said Vicky White, Fermilab’s chief information officer and computing architect for the second run of Tevatron experiments. “Sometimes the success is the data you didn’t collect.”

Even after the trigger system filters out the vast majority of data, there’s still an awful lot left.
When confronted in the 1990s with the amount of data the Tevatron’s Run II was expected to produce, scientists realized they would need 20 times more storage than for the first run. Commercial systems couldn’t handle it, so White’s team made room for the anticipated data explosion by building a homegrown data storage and caching system. The system automatically sorted the information into data that scientists would dip into often and data that could be stored in a place without regular access. The system cached the vast majority of data on tape—the less expensive option—and sent the slice of oft-needed data to disks, allowing scientists far easier access to it.
They also built pipes to move data around the world. The web that connects the world’s information is a complex environment, in which countries and institutions have different networks and plug-ins for moving their own data locally. Data transmitted from an experiment to other regions or to the rest of the world has to move through pipes that are compatible with the networks of everyone who wants to analyze it. So scientists built a multi-network domain that would play nice with the world’s variety of networks.
“Big data is no use unless you can move it around,” White says.
With a network that began in the 1980s and grew, Fermilab partnered with other institutions to share data coming out of the collisions. Anyone on this grid could access data and contribute to high-energy physics analyses, no matter where they were located.

The LHC experiments took the concept of grid computing to the next level, building a globe-spanning network of distributed computing.
In short, says Amber Boehnlein, who leads scientific computing at SLAC, “CERN made an integrated, seamless system that allowed them to take advantage of global resources.”
Today the Worldwide LHC Computing Grid comprises some 200,000 processing cores and 150 petabytes of storage distributed across more than 150 computing centers in 36 countries. (Learn more about this distributed system in Deconstruction: big data.)
By sharing the load of storing, distributing and analyzing the LHC’s staggering data set, the grid allows each member to focus on only part of the data. This is especially important because once a researcher begins to analyze a piece of raw data to recreate particle collisions, that process creates new data, increasing the size of the entire data set exponentially. It’s helpful for this to happen only after the mammoth LHC data set has been chopped up according to collaborators’ needs.
The LHC Computing Grid also allows researchers to access LHC data a little closer to home.
“You don’t want all the thousands of scientists to pounce on the one data set that’s in Geneva,” says Jacek Becla, one of the main designers of the database for the BaBar experiment at SLAC. “It’s much better if you have your own subset that interests you in your own machine. It balances the load.”
Particle physicists’ need to create, process and share their data around the globe helped turn potentially unyielding data sets into dynamic, high-velocity and widespread information.
High-energy physicists’ success at conquering big data is paying off not only for their field, but for astrophysics as well. As they quickly approach the petabyte threshold of data collection, astrophysicists too are beginning to form a federation of research institutions that share the weight of an enormous computing job.
Traditionally, astronomers tended to work in small, separate groups of two or three. This began to change with the Sloan Digital Sky Survey, which in 2008 completed its analysis of one quarter of the night sky. With SDSS, a 200-strong group of scientists at 25 institutions produced 70 terabytes of images of stars and galaxies. Based at Fermilab, SDSS collaboration members built storage systems from scratch. They also quickly figured out how to build and engineer a database of eight years’ worth of collected images, one that could be mined endlessly.
In a matter of years, the Large Synoptic Survey Telescope, which will see first light in 2020, will take astronomy into the petabyte range, producing more than 100 petabytes over 10 years. SLAC is building software that will manage all those petabytes of images as well as the database containing trillions of observations of astronomical objects. Many petabytes, including calibrated images, won’t be stored forever; it would be far too much to keep. Instead, like particle physicists using data from collisions to reconstruct an event, those accessing the LSST database will process images on the fly based on the stored raw data—raw images of celestial objects.
The LSST group may also adopt the LHC tier system of data distribution to share the load among its 200 collaborators.
“We think it’s a good model,” says Becla, who leads the LSST database effort. “It’s likely we’ll accept it for LSST.”
Particle physicists have conquered the collection of big data, the management of complex data and the global distribution of data. Now, together with particle astrophysicists, they’re working on the next step: data democratization.
The CMS experiment at the LHC is organizing its petabytes of data into several tiers of access so almost anyone with an inkling of what to look for can do his or her own analysis.
“One of our goals is to make sure that anybody with a good idea, independent of the resources of a university or lab, has access to the data,” says Lothar Bauerdick, the US CMS computing and software manager.
This mission is similar to that of SDSS and nearly all US space missions. Users download 10 terabytes from the SDSS every month. SLAC’s Instrument Science Operations Center delivers processed data from the Fermi Gamma-ray Space Telescope to NASA’s Fermi Science Support Center, which then makes the data available to the public mere hours after it’s collected.
“It pays to be open and work in collaboration,” says Fermilab’s Brian Yanny, who oversees the SDSS database. “A wider audience will find new ways of getting more out of your data than you had ever imagined.”
The proliferation of information will always push at the limits of our imaginations. But as particle physicists and astrophysicists together work to make data more open, computing technologies more capable and science communities more connected, collaborators become more adept at bringing their gargantuan data sets down to earth—to something accessible, manageable and imaginable.
Once they manage that, scientists can then interpret the data, giving it physical meaning. The 0s and 1s become answers to pressing questions about the universe—new understandings, new parts of the universe to imagine. Big data becomes knowledge.
“The people who are successful at big data are the ones who don’t get overwhelmed by it. They’re managing the data—the data’s not managing them,” says Rob Roser, head of Fermilab’s Scientific Computing Division. “By managing, interrogating and interpreting it, we come to understand the subtle nuances of how this universe works.”